
Your RAG Pipeline Is an Agent Now, Whether You Know It or Not

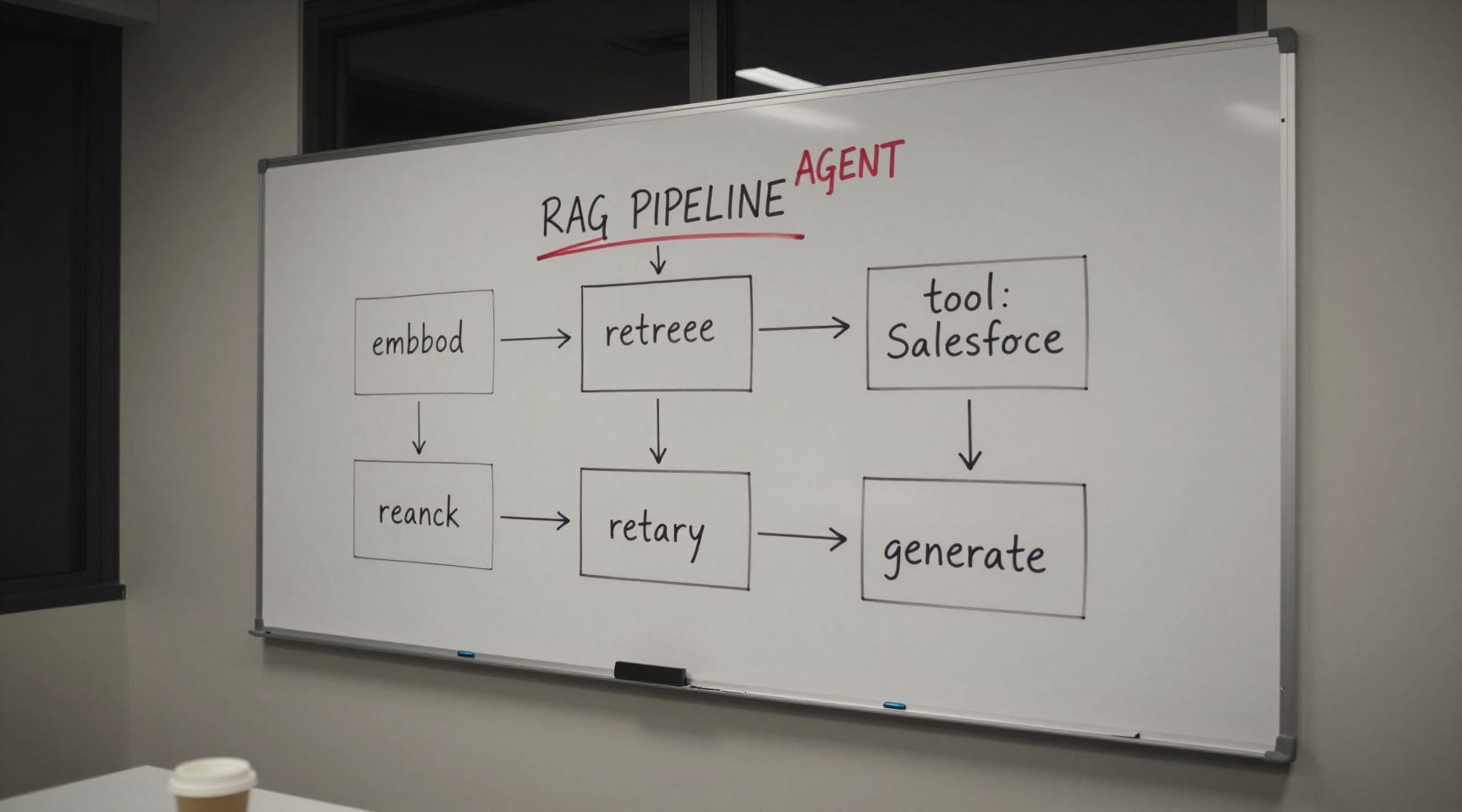
An engineer walked me through his “RAG pipeline” last week and, by the third minute, had described query rewriting, intent classification, multi-hop retrieval across two vector stores, a Cohere reranker, a tool call into Salesforce for live opportunity data, conditional routing between summarization and direct-answer modes, and a retry loop when the str…
